
Становится все более очевидным — по крайней мере, в анекдотических случаях — насколько дорого обходится обучение больших языковых моделей и рекомендательных систем, которые, возможно, являются двумя наиболее важными рабочими нагрузками, приводящими ИИ на предприятие. Но благодаря новой услуге аренды системы для обучения моделей GPT, доступной от производителя систем машинного обучения Cerebras Systems и партнера по облачным вычислениям Cirrascale, у нас теперь есть некоторые фактические цены, которые показывают, сколько стоит запуск той или иной модели GPT в каком масштабе.
Это первые такие общедоступные данные, которые мы увидели из оставшихся выскочек по обучению ИИ, которые на данный момент включают Cerebras, SambaNova Systems, Graphcore и Intel Habana Labs — и, возможно, мы щедры на последнюю, поскольку Intel хочет сократить производственные линии и персонал , поскольку она стремится сократить расходы на сумму от 8 до 10 миллиардов долларов из своих бухгалтерских книг в период до 2025 года .
Информация о ценах, которую Cerebras и Cirrascale обнародовали для проведения специальных тренингов по ИИ GPT на четырех суперкомпьютерах CS-2, была объявлена в связи с партнерством с Jasper, одним из ряда поставщиков приложений ИИ, которые помогают предприятиям всех отраслей и размеры выясняют, как развертывать большие языковые модели для управления их приложениями. Как и все остальные на Земле, Jasper обучает свои модели ИИ на графических процессорах Nvidia и ищет более простой и быстрый способ обучения моделей, чем и зарабатывает на жизнь.
И Джаспер действительно зарабатывает этим на жизнь, по словам Дейва Рогенмозера, соучредителя и главного исполнительного директора компании. У компании около 100 000 платных клиентов, которые используют систему Jasper для всего: от написания блогов до создания контент-маркетинга и создания технических руководств. Эти большие языковые модели еще не генерируют идеальный контент, но при правильном вводе они могут получить его примерно на 70 процентов от необходимого и довольно мгновенно, и это значительно ускоряет процесс создания контента для много компаний. (Хотите верьте, хотите нет, но большинству людей не нравится писать, да и не очень быстро они это делают.)
Компания Jasper, базирующаяся в Остине, была основана в январе 2021 года, привлекла начальный раунд в размере 6 миллионов долларов в июне 2021 года и только что завершила его раундом финансирования серии A в размере 125 миллионов долларов, организованным Insight Partners, который дает компании оценку в 1,5 миллиарда долларов. Это один из многих стартапов, которые предоставляют услуги на основе LLM, и действующие поставщики прикладного программного обеспечения также выясняют, как использовать LLM всевозможными способами для расширения своих моделей.
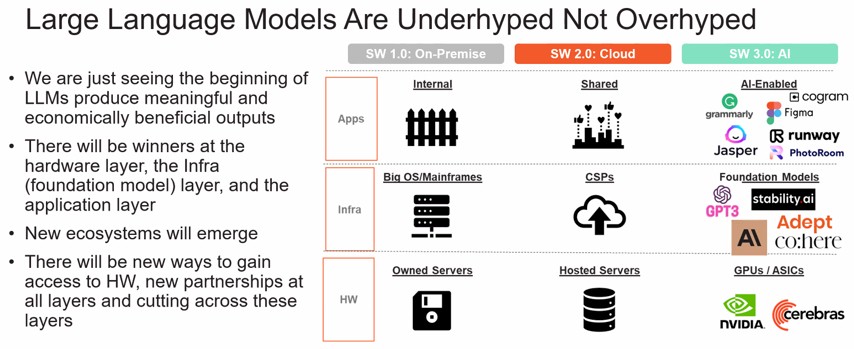
«Мы считаем, что большие языковые модели недооценены и что мы только начинаем замечать их влияние», — объясняет Эндрю Фельдман, соучредитель и главный исполнительный директор компании Cerebras, которая является пионером в области обработки в масштабе пластин, а также Аппаратное обеспечение для обучения ИИ. «На каждом из этих трех уровней экосистемы будут победители и новые эмерджентные игроки — аппаратный уровень, инфраструктурный уровень и базовая модель, а также прикладной уровень. А в следующем году вы увидите стремительный рост и влияние крупных языковых моделей в различных сферах экономики».
То, что Cerebras рекламирует со своим суперкомпьютером с искусственным интеллектом «Андромеда» , который представляет собой набор из шестнадцати систем CS-2 в масштабе пластины, объединенных в единую систему с более чем 13,5 миллионами ядер, которая обеспечивает производительность 120 петафлопс при 16-разрядных плавающих точечная точность с плотной матрицей и в 8 раз больше, чем с разреженными матрицами. Эта система стоит чуть менее 30 миллионов долларов, что является большой суммой даже для такого единорога из Силиконовой долины, как Джаспер. ( В конце концов, это не бум доткомов …) И, следовательно, модель аренды, которую Cerebras и Cirrascale разработали независимо друг от друга и теперь совместно выводят на рынок.
И, как и в случае с любой рабочей нагрузкой, при определенном масштабе и определенном уровне использования, покупка кластера CS-2 будет иметь гораздо больший экономический смысл, чем его аренда, и мы не удивимся. увидеть, как такие компании, как Джаспер, раскошеливаются на это по причинам, которые станут очевидны через секунду.
МОДЕЛЬ УПРАВЛЯЕТ КОНТЕНТОМ, КОТОРЫЙ УПРАВЛЯЕТ МОДЕЛЬЮ
В бизнесе Джаспера есть две движущие силы, которые уводят его от мира параллельных моделей и параллельных данных распределенного обучения ИИ на GPU, в котором есть некоторые болезненные процессы, когда дело доходит до измельчения данных и задач для обучения ИИ. тысячи или десятки тысяч графических процессоров и в любящие объятия Церебра, поддерживающей только параллельные данные.
«Корпоративным предприятиям в первую очередь нужны персонализированные модели, и они очень этого хотят», — объясняет Рогенмозер. «Они хотят, чтобы их обучили их языку, они хотят, чтобы их обучили их базе знаний и каталогам их продукции. Они хотят, чтобы их обучили голосу их бренда — они хотят, чтобы они действительно были продолжением бренда. Они хотят, чтобы их команда по продажам говорила одинаково и мгновенно узнавала информацию о новых продуктах, они хотят, чтобы все говорили в унисон. Когда люди попадают в компанию, они хотят, чтобы они сразу же были в курсе, и все в этой компании говорили, используя определенные слова, а не используяопределенные слова. И они хотят, чтобы это постоянно становилось все лучше и лучше. Это своего рода вторая часть — они хотят, чтобы эти модели стали лучше, и они хотят, чтобы они самооптимизировались на основе их прошлых данных об использовании, на основе производительности. Если они напишут заголовок для рекламы в Facebook, и это окажется победителем, они хотят, чтобы модель могла узнать, что происходит, и иметь возможность самостоятельно оптимизировать это».
Ситуация еще немного сложнее, рассказывает The Next Platform Энди Хок, вице-президент по продуктам Cerebras .
«Одна из вещей, которую мы наблюдаем более широко на рынке за пределами Jasper, заключается в том, что многие компании хотели бы иметь возможность быстро исследовать и разрабатывать эти крупномасштабные модели для конкретных бизнес-приложений», — говорит Хок. «Но инфраструктура, существующая в традиционном облаке, не позволяет легко проводить такие крупномасштабные исследования и разработки. Таким образом, возможность задавать такие вопросы, как: Должен ли я тренироваться с нуля? Или мне следует настроить общедоступную контрольную точку с открытым исходным кодом? Какой лучший ответ? Как наиболее эффективно использовать вычислительные ресурсы для снижения стоимости товаров и предоставления наилучшего обслуживания моему клиенту? Возможность задавать эти вопросы является дорогостоящей и непрактичной во многих случаях с традиционной инфраструктурой».
Вот почему Cerebras и Cirrascale объединили модель аренды Cerebras AI Model Studio, которая работает в инфраструктуре, принадлежащей обеим компаниям, на основе кластеров железа CS-2. Ни один из них не говорит, сколько железа CS-2 они развернули, но архитектура Cerebras, теоретически, позволяет масштабировать его довольно широко, как мы обсуждали в прошлом здесь и там, с 192 узлами CS-2, имеющими в общей сложности На данный момент смоделировано 163 миллиона ядер в одном образе системы.
Бороться за доступность графических процессоров в одном из крупных облаков — это одно, а разбивать модели и данные для работы на сотнях, тысячах или десятках тысяч графических процессоров — это совсем другое. Платить за это — другое дело.
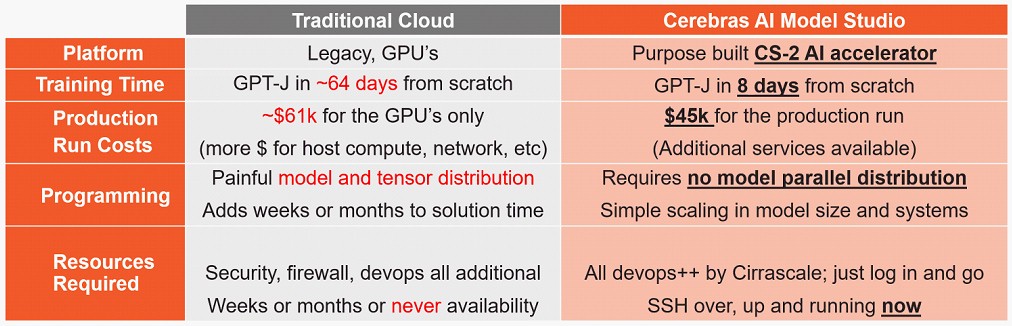
Таким образом, центральной темой AI Model Studio, созданной Cerebras и Cirrascale, является предсказуемость, а не просто расплывчатое заявление о том, что модели AI могут работать в 8 раз быстрее и за полцены по сравнению с использованием графических процессоров в Amazon Web Services.
«У нас есть исследовательские лаборатории ИИ и некоторые финансовые учреждения в качестве клиентов, и все они хотят обучать свои собственные модели и использовать свои собственные данные для повышения точности этих моделей», — говорит Пи Джей Го, соучредитель и главный исполнительный директор Cirrascale. . «И они хотят сделать это быстро и по разумной цене. И, наверное, самое главное, они хотят предсказуемой цены. Они не хотят выписывать поставщику облачных услуг незаполненный чек, чтобы иметь возможность обучать модель».
Итак, идеальной иллюстрацией того, что вычислительные мощности — это деньги, является стоимость услуги AI Model Studio в кластере CS-2 с четырьмя узлами при обучении запуску GPT-3 с нуля:
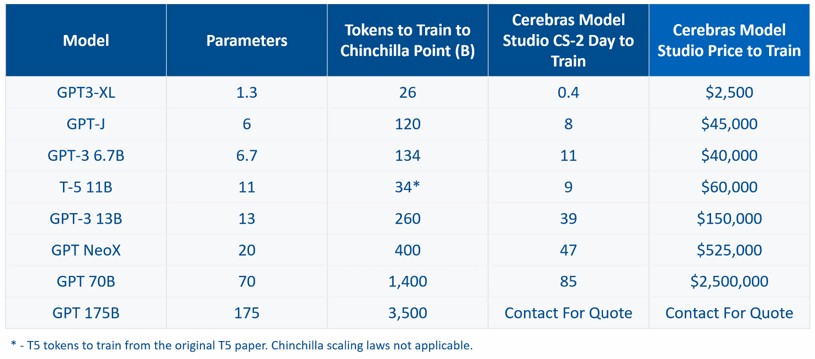
«Точка шиншиллы» — это уровень данных, измеряемый в токенах, который требуется для эффективного обучения модели и который сходится к правильному ответу. (С большой языковой моделью вы узнаете это, когда читаете или слышите ее.) Отдача от слишком большого количества данных через модель снижается, и иногда вы можете зайти слишком далеко, точно так же, как вы можете переоценить статистическую кривую, если вы стать слишком агрессивным. (Вы тоже знаете это, когда видите это.)
Очевидно, что размер модели по параметрам и количество токенов масштабируются вместе, и в целом можно сказать, что чем больше модель, тем больше времени требуется для обучения на заданной конфигурации. Опять же, это само собой разумеющееся, потому что вы просто загружаете и возитесь со все большим и большим количеством данных, поскольку усилия по обучению ИИ расширяются, чтобы добиться все лучших и лучших результатов.
Вы нас знаете, мы не можем оставить таблицу, подобную той, которую создали Cerebras и Cirrascale, в одиночку, поэтому мы немного подсчитали стоимость каждого параметра, а также токенов в день обработки и долларов в день потраченных долларов. Мы также попытались выяснить цену и производительность трех крупнейших моделей — GPT NeoX, GPT 70B и GPT 175B — работающих на машине класса Andromeda с 16 узлами CS-2 вместо показанных четырех узлов CS-2. в исходной таблице.
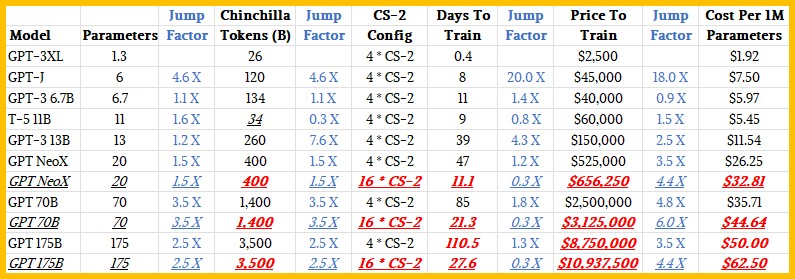
Эти факторы перехода, которые мы вводим, нуждаются в объяснении. В конечном счете, мы все хотим знать, как количество дней для обучения и цена подскочили с каждым расширением модели GPT, а затем мы хотим знать, как мы можем масштабировать железо, чтобы мы могли ускорить время обучения. Факторы перехода рассчитывают дельту при переходе от одной модели GPT к следующей, и мы пропускаем ожидаемую модель T-5 11B по сравнению с прогоном GPT-3 6.7B. (Модель трансформатора T5 от Google, показанная на диаграмме, не является моделью GPT-3, а представляет собой LLM.) Таким образом, переход к GPT-3 13B сравнивается с GPT-3 6,7B, а не с запуском T-5 11B. И так далее.
В нижней части шкалы параметров GPT-3 в кластере CS-2 с четырьмя узлами увеличение количества параметров приводит к гораздо большему времени обучения, чем можно было бы ожидать. Переход от 1,3 миллиарда параметров к 6 миллиардам параметров означает увеличение объема данных в 4,6 раза, но приводит к увеличению времени обучения в 20 раз. Переход с 6,7 млрд до 13 млрд параметров — это еще одно увеличение в 1,9 раза, но время обучения увеличивается в 3,5 раза. При запуске GPT NeoX параметры увеличиваются в 1,5 раза, но время обучения увеличивается только в 1,2 раза. Так что это не совсем линейно, поскольку модели увеличиваются в размерах.
Как мы уже говорили ранее в этом месяце, машины CS-2 масштабируются почти линейно. Четыре узла почти вдвое превышают работу двух узлов, восемь узлов почти вдвое превышают работу четырех узлов, а шестнадцать узлов почти вдвое превышают работу восьми узлов. Когда мы спросили, увеличивается ли цена также линейно, Фельдман сказал, что это не кажется справедливым, что достаточно верно для архитектур NUMA, которые становятся дороже по мере увеличения масштаба. Фельдман предположил, что «четырехкратная производительность по пятикратной цене» — это хороший способ подумать о том, как шестнадцать узлов CS-2 сравнить с четырьмя узлами.
Мы не знаем, будет ли этот алгоритм масштабироваться до установки с двумя или одним узлом, снижая стоимость на 20 процентов при уменьшении размера кластера CS-2. Но предположительно будет. Но опять же, зачем вам пытаться тренироваться дольше на меньшей системе, когда вы можете иметь большую систему в течение более короткого времени? Вы бы сделали это только в том случае, если бы у вас был ограниченный бюджет, а время не имело существенного значения.
Отсюда и наши предположения о затратах, изложенные выше. Очевидно, что в кластере из четырех узлов стоимость обработки каждого набора параметров возрастает по мере того, как модели становятся толще. Для модели GPT-3XL это всего 1,92 доллара за 1 миллион параметров, но по цене, установленной Cerebras и Cirrascale, для модели GPT 70B она составляет 35,71 доллара. Цена за 1 миллион параметров увеличивается в 18,6 раз, а количество параметров увеличивается в 53,8 раза.
Мы предполагаем, что для запуска модели GPT с 500 миллиардами параметров в кластере CS-2 с четырьмя узлами потребуется около года, а в кластере с 16 узлами вы сможете выполнить 2 триллиона параметров в год. Или, по нашим оценкам, это позволит вам с нуля тренировать GPT 175B с нуля более 13 раз — вызывайте его раз в месяц с запасом. Вот что вы получите, раскошелившись на 30 миллионов долларов на свой собственный суперкомпьютер Andromeda CS-2. Но аренда 13 тренировочных заездов GPT 175B может стоить вам порядка 142 миллионов долларов, если наши предположения о том, как цены и производительность будут расти в масштабах услуг AI Model Studio, верны.
Итак, некоторые люди будут арендовать оборудование для обучения, а затем, когда им потребуется больше обучать, а также обучать более крупные модели, экономика вынудит их покупать.
Спонсоры статьи: